Last week, OpenAI announced and released its latest multimodal model named GPT-4. In contrast to its predecessor, GPT-3, it is more knowledgable, creative, handles lengthier text input, and is capable of interpreting images. The company claims that the new technology “exhibits human-level performance on various professional and academic benchmarks.” While I’m not convinced that GPT-4 will be replacing detection engineering teams anytime soon, I believe it’s going to change how professionals in every component of a cybersecurity program will work.
With that, I signed up for the ChatGPT Plus subscription and set out to determine how detection engineers can leverage GPT-4 to assist them in their day-to-day work. In the following article, I’ll walk you through four interesting use cases I found in my first hour of working with GPT-4.
Drafting Documentation
Although it can be time consuming and at times seems tedious, documentation is potentially the most important component of detection content.
Let’s see if GPT-4 can author Alerting and Detection Strategy (ADS) documentation based on a short description of a detection use case involving the malicious use of PowerShell.exe:

Now let’s see how it documents a security event data source:

Not bad, really, but I don’t recommend solely relying on GPT-4 to author documentation. I think the result it produces can serve as a rough draft that can prime a detection engineer for authoring proper documentation.
Prototyping Use Cases
Let’s throw a brainstorming session at GPT-4 to see how useful it can be during the early stages of content development. How about detecting the use of malicious Python packages?
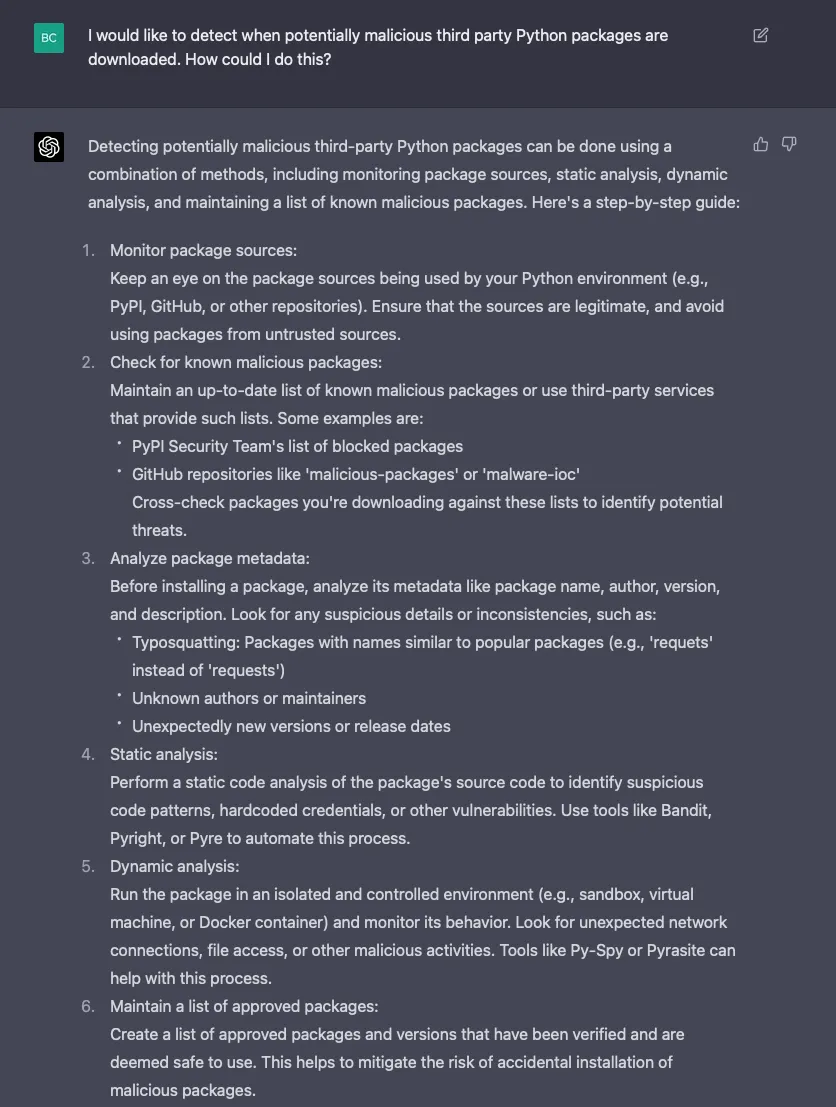
Let’s take the use of Bandit—mentioned in #4 above—a few steps further:
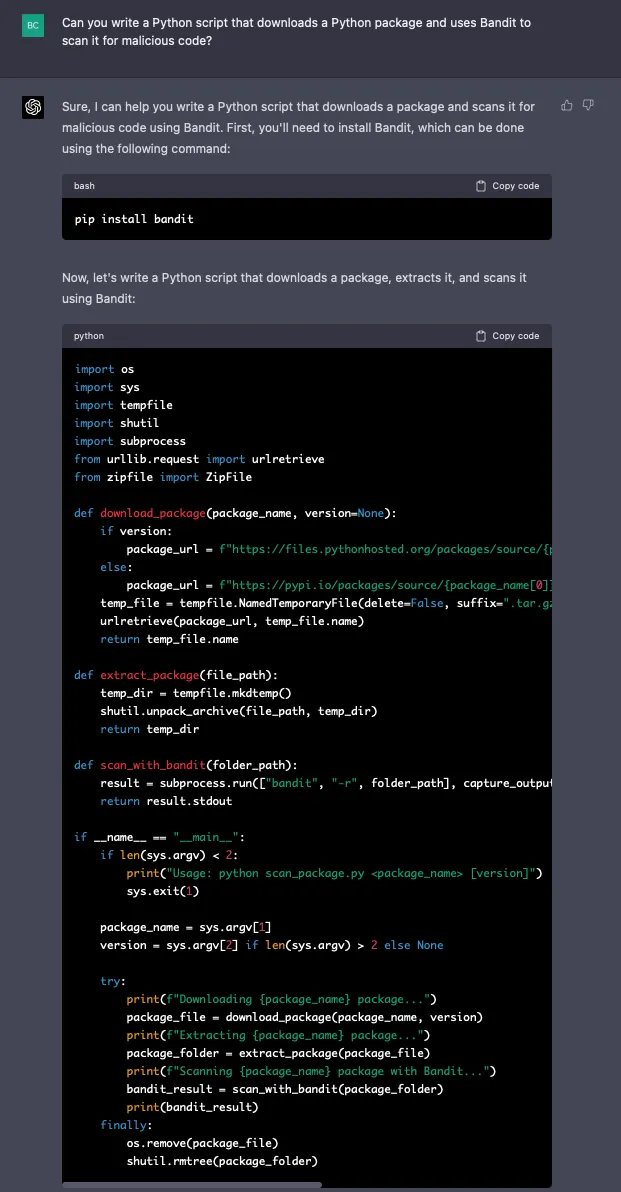
Let’s see if it will add some useful docstrings:
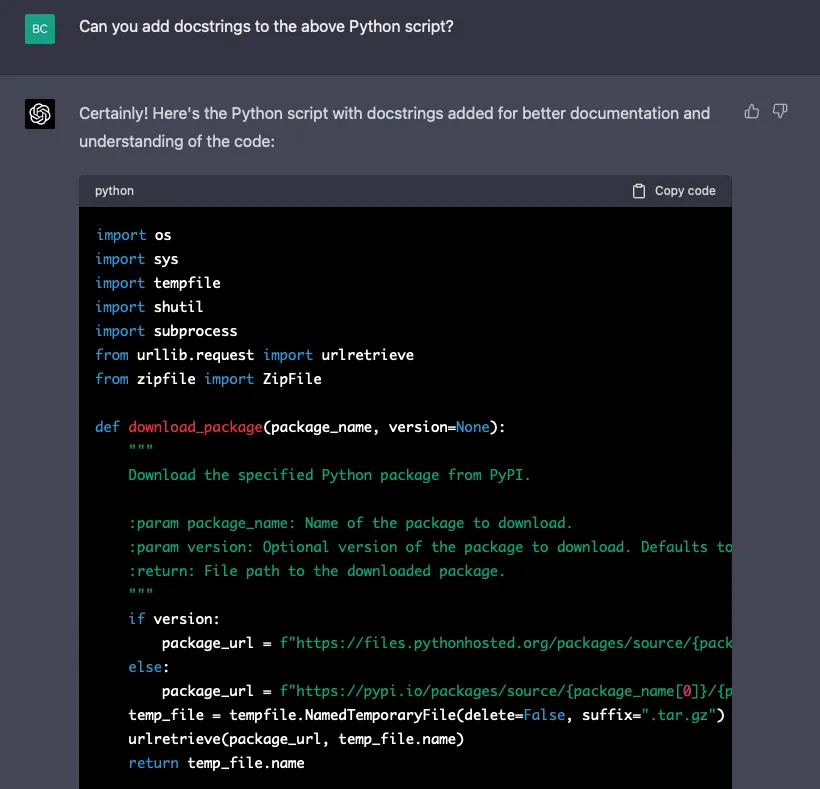
In testing, the script GPT-4 produced above is partially successful and its use of Bandit through the subprocess module is less-than-ideal. An error results when running it without specifying a package version. However, it does successfully run when a version is specified.
Here’s an example scan of urllib3 version 1.26.15:
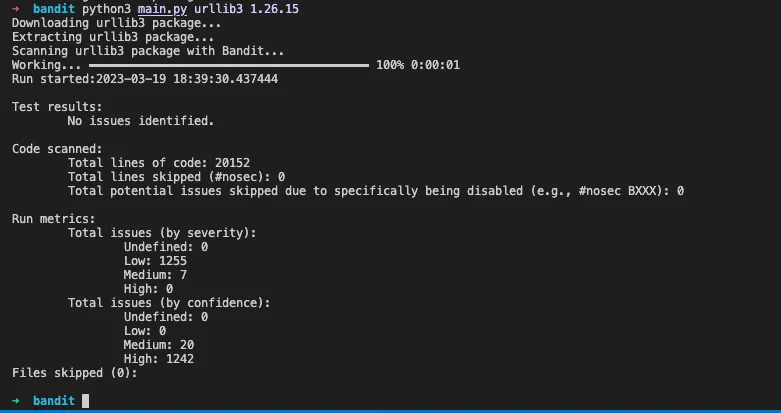
I’m guessing most Python scripts created by GPT-4 will need some thorough testing, debugging, and refactoring. Nevertheless, it’s capable of producing a solid foundation.
Let’s see if GPT-4 can port this script to a Palo Alto xSOAR integration:
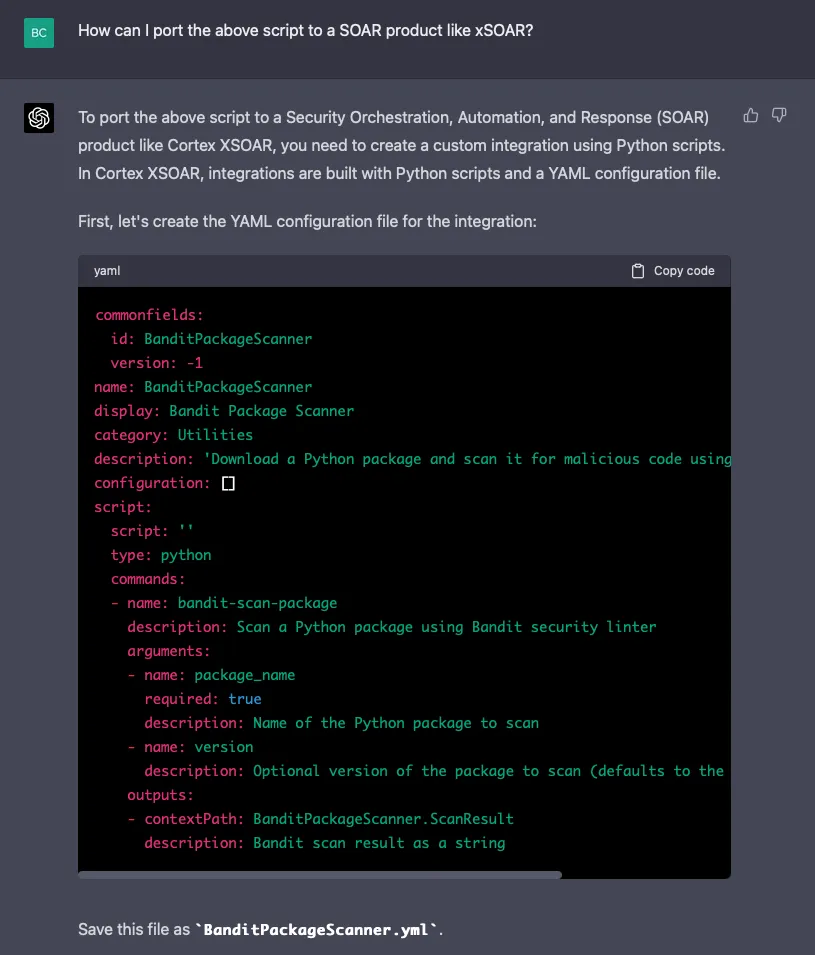
Continued…
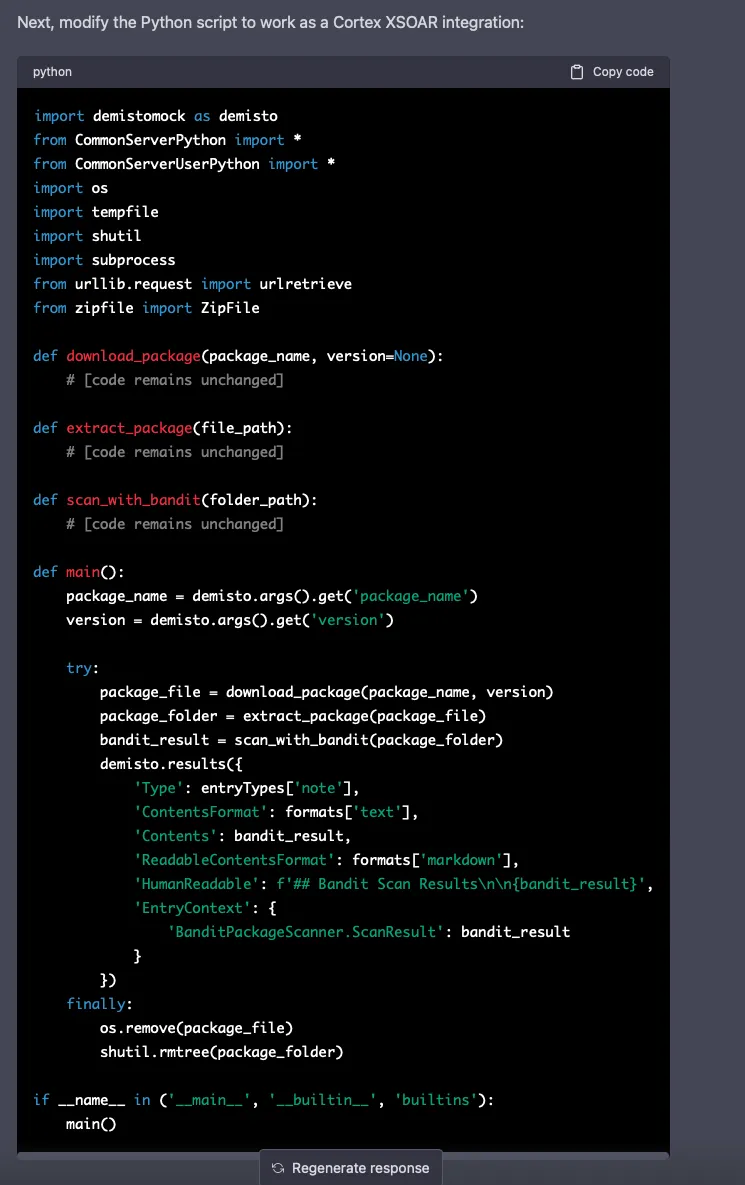
Finally…
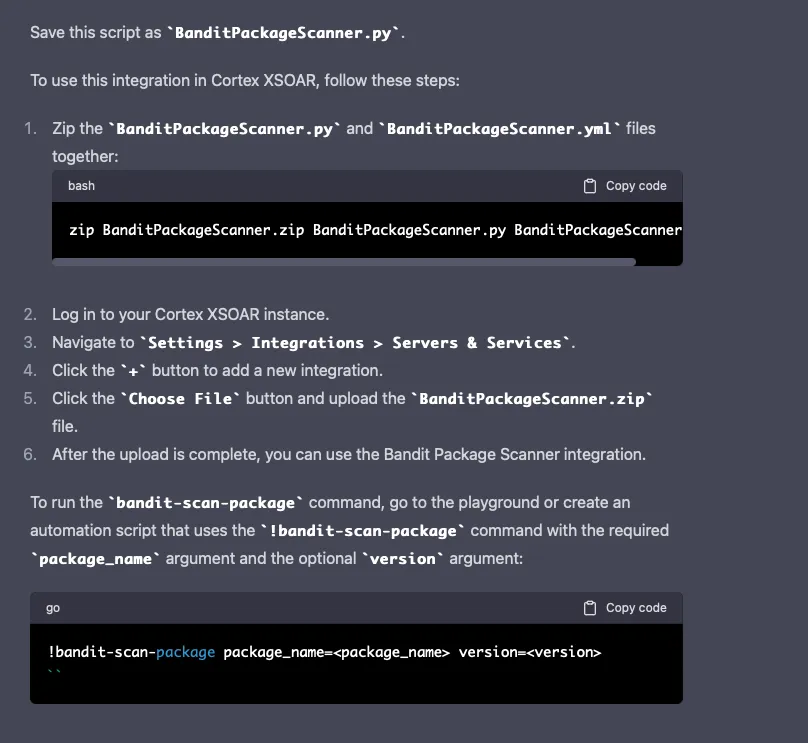
Unfortunatley, I don’t have access to a development instance of xSOAR to test this integration. Based on my experience producing integrations in xSOAR, it seems this will likely produce a working integration.
Rule Conversion & Implementation
While several tools like Uncoder already exist to convert detection rules, GPT-4 is capable of converting rules between various formats.
Let’s see how it handles conversion of the Sigma Rule “Copy Passwd Or Shadow From TMP Path” to Splunk SPL:
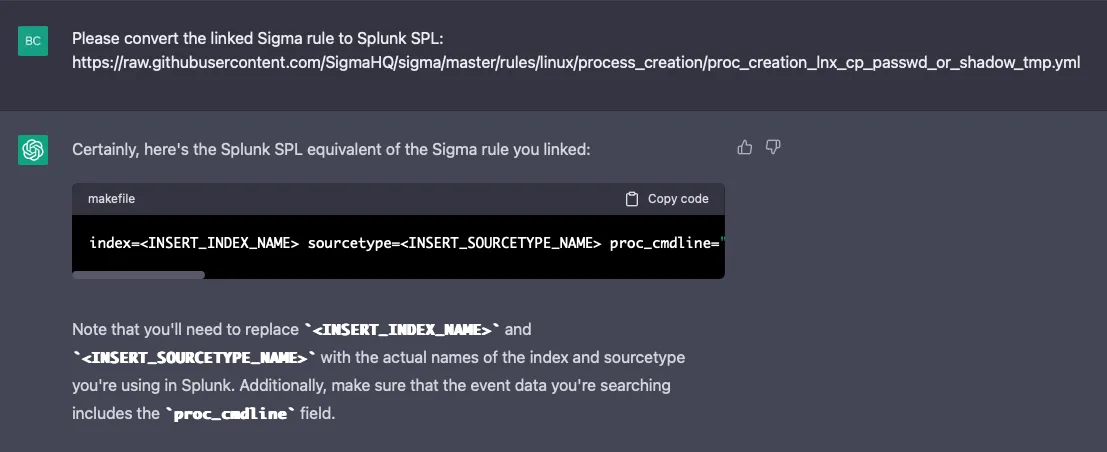
index=<INSERT_INDEX_NAME> sourcetype="<INSERT_SOURCETYPE_NAME>"
proc_cmdline="*cp /etc/passwd* /tmp/*" OR
proc_cmdline="*cp /etc/shadow* /tmp/*" OR
proc_cmdline="*cp /etc/master.passwd* /tmp/*" OR
proc_cmdline="*cp /etc/group* /tmp/*" OR
proc_cmdline="*cp /etc/gshadow* /tmp/*" OR
proc_cmdline="*cp /etc/security/opasswd* /tmp/*" OR
proc_cmdline="*cp /etc/security/group* /tmp/*"
The above SPL will technically work, but it’s sloppy. The query will perform extremely poorly in an enterprise Splunk deployment.
Let’s see if it can generate a tstats-based search instead:
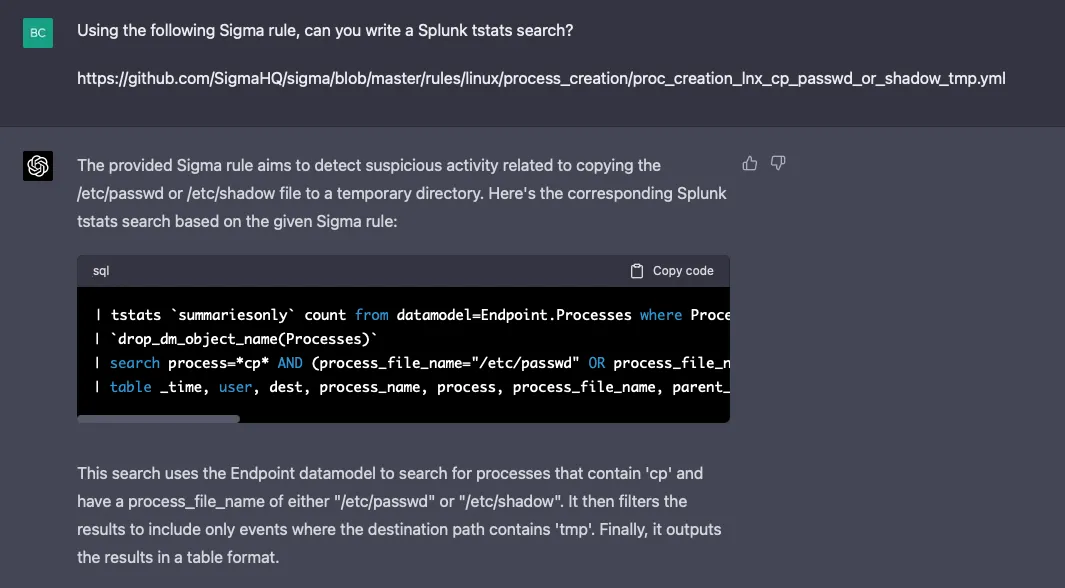
| tstats `summariesonly` count from datamodel=Endpoint.Processes where Processes.process=*cp* Processes.process_file_name IN ("/etc/passwd", "/etc/shadow") by Processes.user, Processes.dest, Processes.process_name, Processes.process, Processes.process_file_name, Processes.parent_process_name, _time span=1s
| `drop_dm_object_name(Processes)`
| search process=*cp* AND (process_file_name="/etc/passwd" OR process_file_name="/etc/shadow") AND dest=*tmp*
| table _time, user, dest, process_name, process, process_file_name, parent_process_nameThere are a few flaws in the above SPL—most notably, the fields targeted by the tstats-based search do not exist in the default Endpoint.Processes Splunk data model. It seems GPT-4 could use some more feedback and training on SPL.
To take it a step further, let’s ask GPT-4 to generate a Splunk savedsearches.conf file (based on the above result):
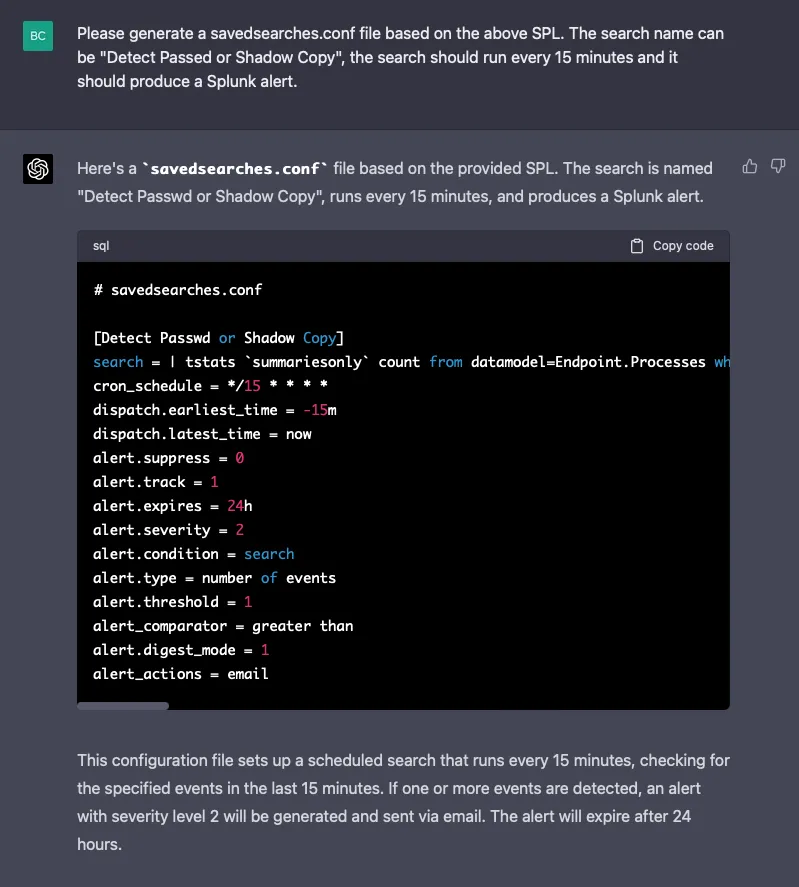
Finally, let’s see if it is capable of bundling the above savedsearches.conf file into a Splunk Technical Add-on:
Instead, it provides me with accurate instructions on how to make that happen.
Data Identification & Normalization
Let’s throw an NGINX access log event at GPT-4 to see if it understands the data and the importance of each field.
Here’s the NGINX log entry:
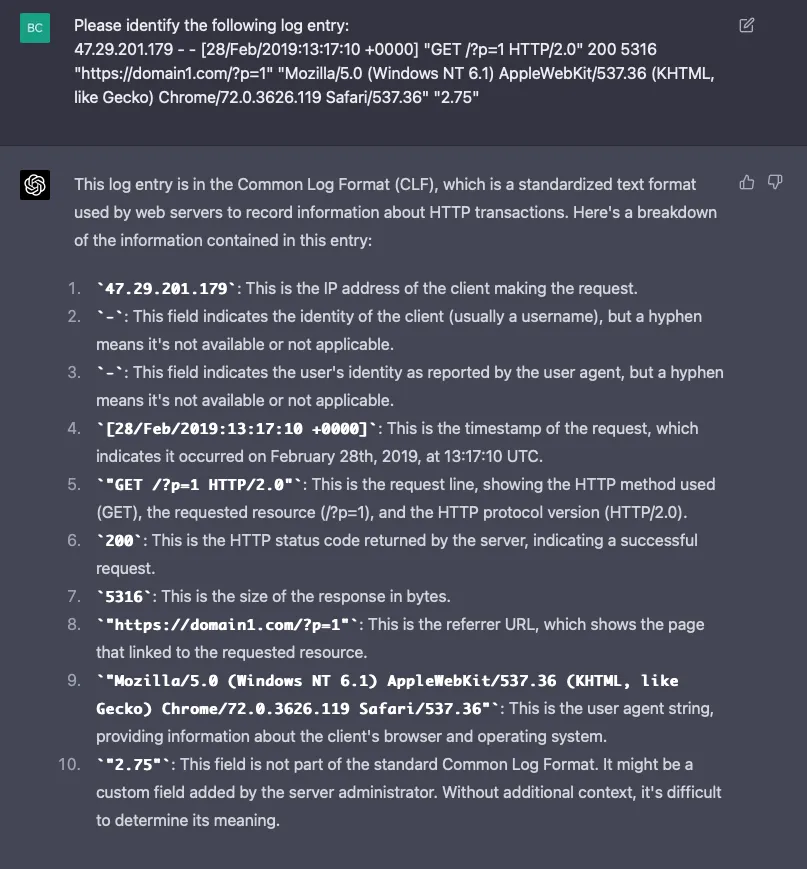
47.29.201.179 - - [28/Feb/2019:13:17:10 +0000] "GET /?p=1 HTTP/2.0" 200 5316 "https://domain1.com/?p=1" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36" "2.75"
Ok, let’s see if it can normalize the data:
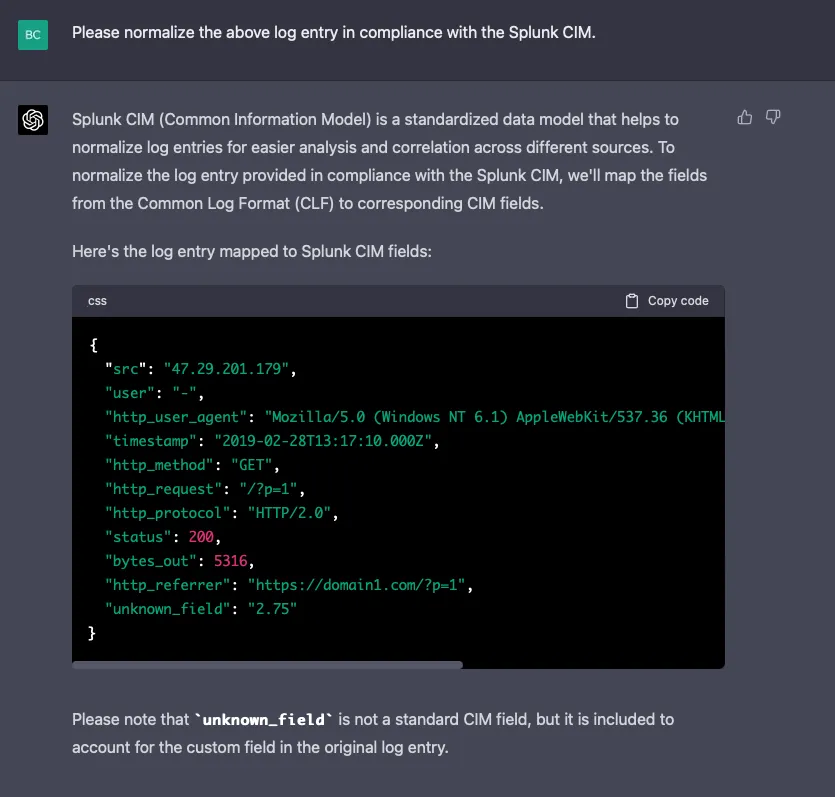
Lastly, let’s see if it’s able to write field extractions using a regex:
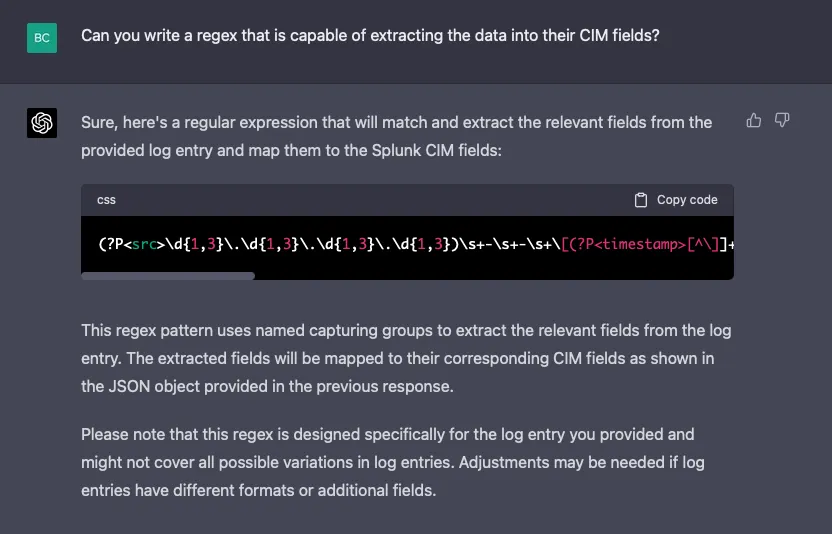
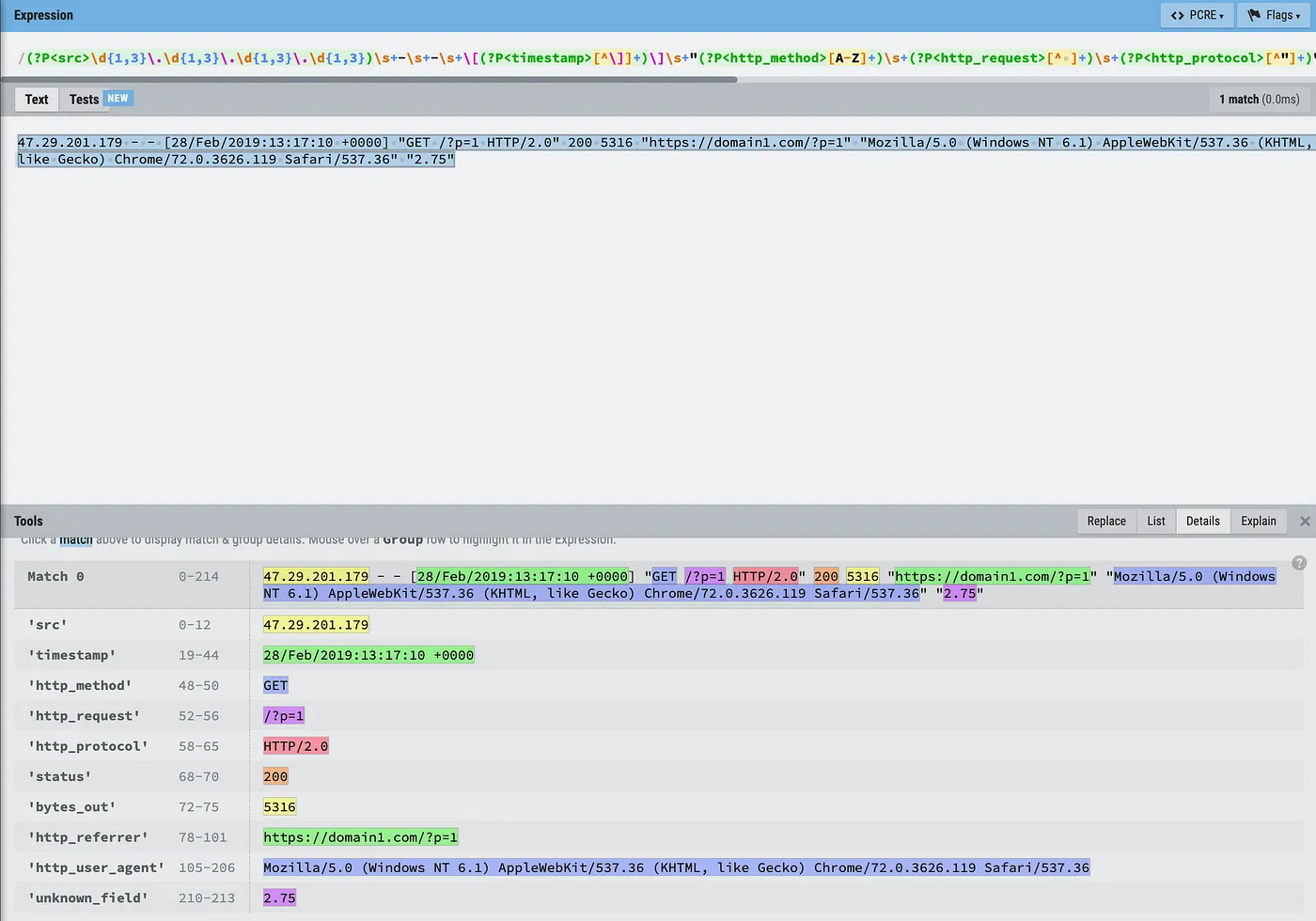
(?P<src>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})\s+-\s+-\s+\[(?P<timestamp>[^\]]+)\]\s+"(?P<http_method>[A-Z]+)\s+(?P<http_request>[^ ]+)\s+(?P<http_protocol>[^"]+)"\s+(?P<status>\d+)\s+(?P<bytes_out>\d+)\s+"(?P<http_referrer>[^"]*)"\s+"(?P<http_user_agent>[^"]+)"\s+"(?P<unknown_field>[^"]+)"
This regex works swimmingly:
Conclusion
In summary, GPT-4 is far from perfect. It produces results that should be received with skepticism, and validated and tested for accuracy. It seems that much like using the appropriate terms in a search engine, you must ask GPT-4 the right questions with the appropriate level of detail to yield the most accurate results.
I believe GPT-4 is an excellent supplemental tool for detection engineers. I’m excited to see how it improves as the tool continues to grow, see more use, and receive more feedback. When used correctly, I think the technology will provide great value to functions across a cybersecurity program.